缓存击穿 之 布隆过滤器 - redis系列
在高并发系统架构中,缓存是提升性能的关键组件。
但是,有个致命的问题:当系统遭遇大量对不存在键值的请求时,会导致缓存穿透现象。为应对这一挑战,业界主要采用两种解决方案:布隆过滤器和缓存空值。其中,布隆过滤器适用于大规模复杂场景,而缓存空值则更适合小规模应用。
本文将探讨如何在Redis布隆过滤器的集成使用,并通过实例详解其实现原理。
1. 布隆过滤器原理解析
1.1 核心概念
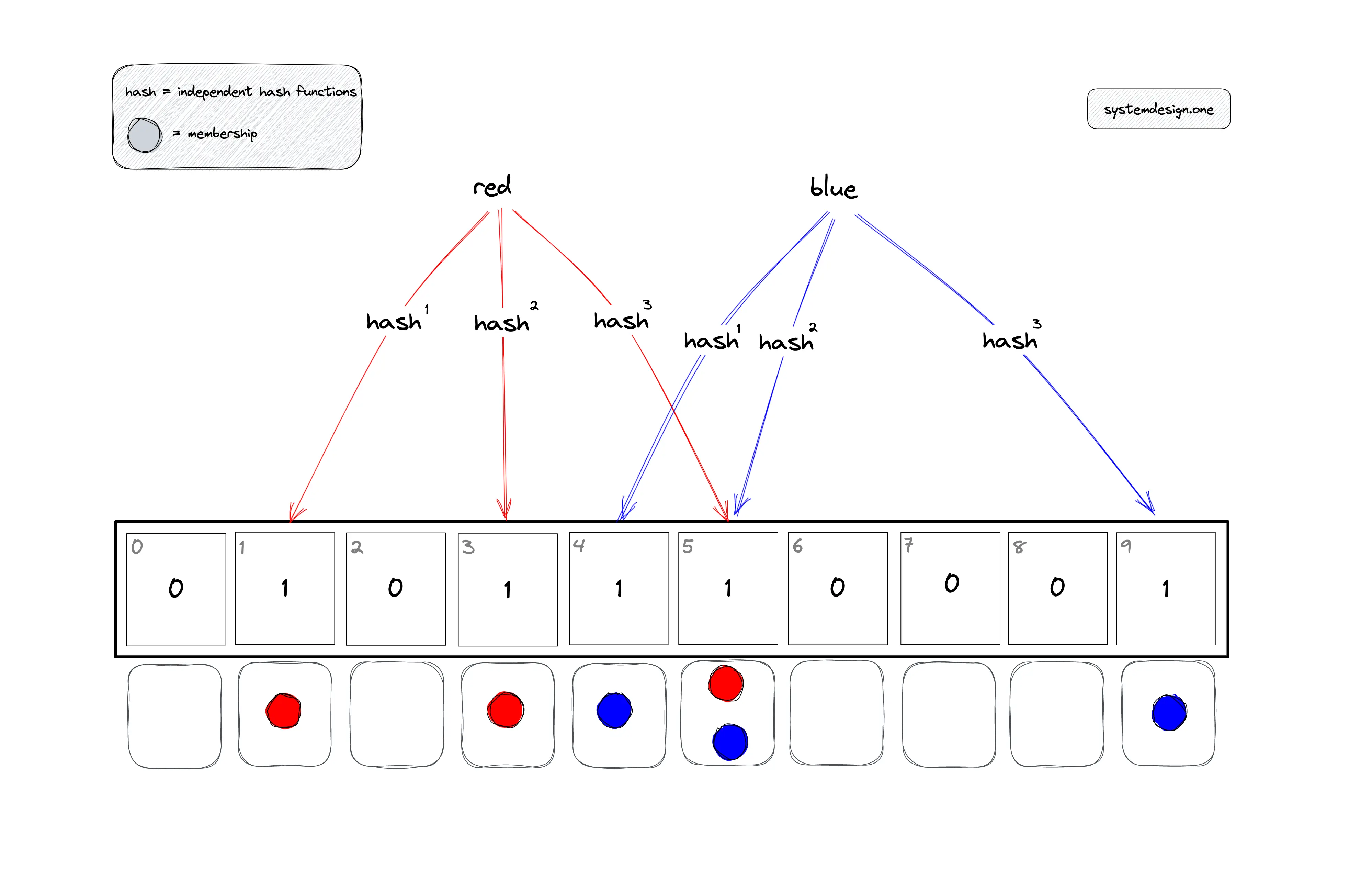
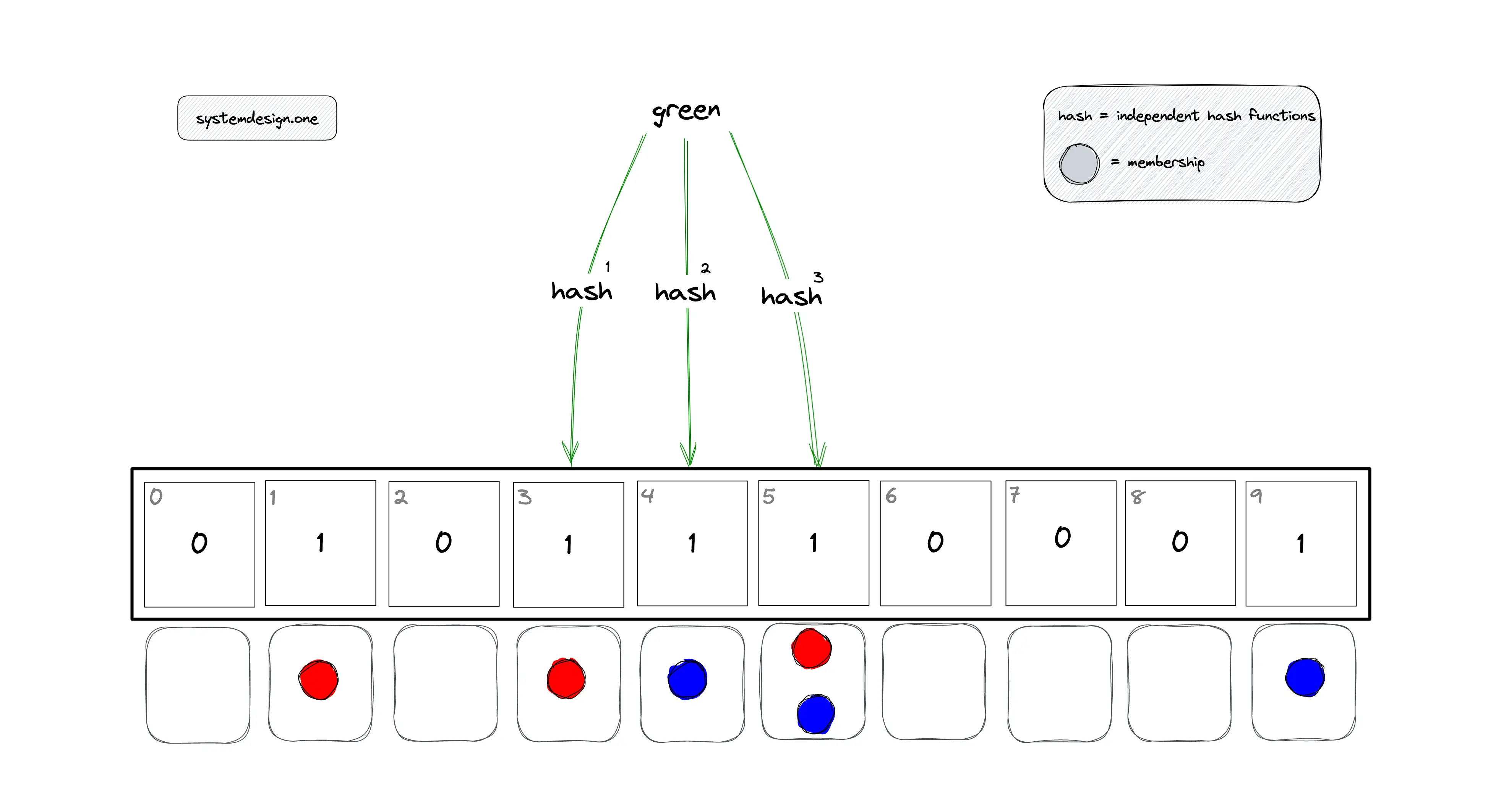
布隆过滤器是一种高效的概率性数据结构,专门用于快速判断元素是否存在于集合中。它具有以下特性:
- 极致的空间效率:相比传统数据结构,布隆过滤器能将空间占用降至最低
- 概率性判断:可以100%确定元素"不存在",但对于"存在"的判断存在小概率误判
- 不可逆性:一旦元素被添加,无法删除(这也是其局限性之一)
1.2 应用场景
布隆过滤器在实际开发中有着广泛的应用:
-
防止缓存穿透
- 快速判断请求的key是否存在
- 避免无效查询到达数据库层
-
海量数据去重
- 网页URL去重
- 垃圾邮件过滤
- 用户行为去重
-
分布式系统
- 分布式缓存的key预判
- 分布式爬虫的URL判重
-
安全领域
- 恶意URL检测
- 黑名单过滤
- 密码强度检查
-
推荐系统
- 用户已读内容过滤
- 新闻推荐去重
- 广告投放去重
-
限流场景
- 接口访问频率控制
- 用户行为限制
2. Redis布隆过滤器实现
2.1 环境准备
首先在Spring Boot项目中添加必要的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.20.0</version>
</dependency>
2.2 Redis配置
在application.yml中配置Redis连接信息:
spring:
redis:
redisson:
config: |
singleServerConfig:
address: redis://localhost:6379
password: redis123456
timeout: 3000
2.3 Redisson配置类
@Configuration
public class RedissonConfig {
@Autowired
private RedissonProperties redissonProperties;
@Bean
public RedissonClient redissonClient() throws Exception {
Config config = Config.fromYAML(redissonProperties.getConfig());
Redisson.create(config);
log.info("Redisson启动成功");
return Redisson.create(config);
}
}
3. 布隆过滤器核心实现
3.1 服务层实现
@Service
@Slf4j
public class BloomFilterService {
private static final String BLOOM_FILTER_NAME = "bloomFilter";
@Autowired
private RedissonClient redissonClient;
public void initBloomFilter(long expectedInsertions, double falseProbability) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);
bloomFilter.tryInit(expectedInsertions, falseProbability);
}
public void addToBloomFilter(String key) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);
bloomFilter.add(key);
}
public boolean mightContain(String key) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);
return bloomFilter.contains(key);
}
}
7. 最佳实践与性能优化
7.1 性能调优建议
-
合理设置初始容量
- 预估数据规模
- 留足增长空间
- 定期调整参数
-
优化误判率
- 根据业务容忍度设置
- 权衡空间成本
- 动态调整参数
7.2 注意事项
- 定期重建布隆过滤器以维持准确性
- 监控误判率变化
- 建立性能基准
- 制定容灾方案
8. 总结
布隆过滤器作为一种高效的概率性数据结构,在当代分布式系统中扮演着越来越重要的角色。通过Spring Boot 3和Redis的完美结合,我们能够轻松实现这一强大的功能。虽然它可能存在小概率误判,但在处理海量数据、防止缓存穿透等场景中,仍然是一种不可或缺的解决方案。
关键要点:
- 空间效率与查询性能的完美平衡
- 支持分布式场景的可扩展性
- 配合Redis实现高可用
- 适用于多样化的业务场景
💬 评论